一、引 言
随着金融体制改革的不断深化和发展,金融企业间的竞争越来越激烈。在网络服务质量等方面的差别逐渐减少的情况下,为了提高市场竞争力,金融企业都在寻求改善客户服务质量的方法。它们迫切地需要提高企业内部的科学决策能力,增强在市场经营等方面的正确判断能力。客户资源是金融企业最重要的核心资源。只有充分细致地认知客户、了解客户的差异化,才能为客户提供更好的服务,才能提高客户满意度和忠诚度,给金融企业带来收入和利润。提高金融企业的市场竞争地位。数据挖掘技术(Data Mining简称DM)的应用可以帮助金融企业分析客户消费行为,识别客户特征,辅助金融企业进行有效的市场营销和客户服务。金融企业都积累了海量的电子化的业务运营数据,通过数据仓库和数据挖掘技术,可以从这些用户的数据中发现很多有价值的信息,例如用户的消费行为分析特征等。根据这些消费行为特征,市场部门就可以提供针对性更强的市场服务策略,并且节约了市场营销的成本。
经营分析支持系统应能够集成专业的数据挖掘工具,在客户细分、信用度分析、客户流失分析等方面建立相应的数据挖掘模型,以便业务分析人员进行深层次的分析和预测。因此,结合企业实际情况,利用数据仓库和数据挖掘等技术建立经营分析支持系统能够极大地提高国内金融企业的业务支撑能力,丰富企业的业务应用内容,全面实施客户关系管理,为客户提供个性化服务,同时为管理和决策提供强有力的依据,全面提高竞争能力,增强企业整体盈利能力,缩短与国际金融企业在运营管理能力方面的差距。
二、基于数据挖掘技术的经营分析支持系统框架
经营分析支持系统与传统的MIS系统既有联系又有区别。传统的MIS系统一般用来协助工作人员处理日常业务.减少重复劳动。而经营分析支持系统是一个决策支持系统(Decision Support System,简称DSS),需借助一定的技术和手段得以在现实中应用,如数据仓库(DW)技术、联机分析处理(OLAP)、数据挖掘(DM)等,从而为企业各个不同的管理层提供决策支持。
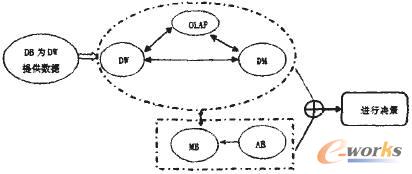
1.DW:实现对决策主题数据的存储和综合.为经营分析支持系统提供数据存储和组织的集成。它对底层数据库中的数据进行集成、转换、综合,组织成面向全局的数据视图。
2.OLAP:实现多维数据分析。从DW中的集成数据出发,构建面向分析的多维数据模型,再使用多为分析方法从多个不同的视角对多维数据进行分析、比较。
3.DM:挖掘DW中的知识。以数据仓库和多维数据库中的大量数据为基础,自动地发现数据中的潜在模式,并以这些模式为基础自动地作出预测。
4.MB(Model Base,模型库):实现多个广义模型的组合辅助决策。模型是为了交流认识而形成的关于客观存在问题的框架。模型库是联系决策问题、数据与模型的桥梁,它将多个模型以一定组织形式存储起来。
5.AB(Algorithm Base,算法库):为求解模型库提供算法,是模型应用的后援系统。方法是具有特定功能的模块化程序设计单位,具体地说是一个过程算法,它具有共享性。算法库是算法可扩充的集合。
三、采用的关键技术
(一)数据挖掘技术
数据挖掘是一个抽取和表示新知识的流程。通过分析具体数据,发现确定有效的、新颖的、有潜在使用价值的、以往不为人知的、最终可理解的信息,为企业良好运营和决策部门作出重要决策提供帮助。确切地说,数据挖掘是一种知识发现的过程,它主要基于统计学、人工智能、机器学习等技术,高度自动化地分析数据,做出归纳性的推理。从中挖掘出潜在的模式,并对未来情况进行预测,以辅助决策者评估风险、做出正确的决策。数据挖掘与联机分析处理都是分析型工具。联机分析处理作为验证型分析工具,更多地依赖用户输入的问题和假设,使得用户能够快速地检索到所需要的数据,而数据挖掘能够自动地发现隐藏在数据中的模式。常用数据挖掘工具有:Microsoft的Analysis Service、SAS Enterprise Miner,DBMiner、SPAS Climentine和IBM Intelligent Miner for data。
(二)ETL技术
经营分析支持系统三层结构中的数据获取层功能是将数据从数据源经过必要的处理后加载到数据仓库系统中。典型的数据获取过程包括:源数据分析、源数据映射、ETI,以及数据审计。ETL即数据抽取、转换和加载。是数据仓库实现过程中,将数据由数据源系统向数据仓库加载的主要过程。从功能上看,整个ETI,包括三个部分:
·数据抽取:从数据源系统抽取数据仓库系统需要的数据;
·数据转换:将从数据源获取的数据转换按数据仓库要求的形式,对数据进行转换;
·数据加载:将数据装入数据仓库。
(三)数据仓库技术
数据仓库是支持管理决策过程的、面向主题的、集成的、随时间而变的、持久的数据集合。数据仓库是按照企业整体的信息模型、尽可能以最小的业务单元来组织并存储数据,这样既能保汪数据访问的灵活性,又可保证最少量的数据冗余。在数据仓库的实施过程中,对于某些主题的业务分析问题,可能会按照主题采用数据集市的方式对数据进行进一步的组织,所以在数据仓库的基础之上根据分析需求会创建相应的从属的数据集市。数据仓库是企业经营分析支持系统的核心。
(四)OLAP分析技术
联机分析处理(OLAP)是针对特定的分析主题,设计多种可能的观察形式,设计相应的分析主题结构(即进行事实表和维表的设计),使管理决策人员在多维数据模型的基础上进行快速、稳定和交互性的访问,并进行各种复杂的分析和预测工作。
四、数据挖掘技术在金融领域中的应用情况
(一)数据挖掘技术分类
在实际应用中,数据挖掘主要采用以下几种方法进行模式的发现:
●预测型方法通常包含以下几种:
1.分类/决策树算法
分类就是找出一个类别的概念描述。它代表了这类数据的整体信息,即该类的内涵描述,并用这种描述来构造模型,一般用规则或决策树模式表示。分类是利用训练数据集通过一定的算法而求得分类规则,分类可被用于规则描述和预测。分类模式是一个分类器,能够把数据集中的数据项映射到某个给定的类上。分类模式往往表现为一棵分类树,根据数据的值从树根开始搜索,沿着数据满足的分支往上走,走到树叶就能确定类别。
分类以及决策树算法在金融企业领域中主要应用于大客户特征的识别、客户群体的细分等方面。
2.回归分析
回归模式的函数定义与分类模式相似,它们的差别在于分类模式的预测值是离散的,回归模式的预测值是连续的。
回归分析在金融企业领域中主要应用于业务预测等方面。
3.时间序列分析
时序模式是指通过时间序列搜索出的重复发生概率较高的模式。与回归一样,它也是用己知的数据预测未来的值,但这些数据的区别是变量所处时间的不同。支持时间序列模式,能够根据数据随时间变化的趋势预测将来的值,能够处理时间的特殊性质,如一些周期性的时问定义(例如:星期、月、季节、年)等。
时间序列分析在金融企业领域中主要应用于业务预测、业务优化等方面。
●描述型方法通常包含以下几种:
1.关联分析
关联规则挖掘是由Rakesh Apwal等人首先提出的。两个或两个以上变量的取值之间存在某种规律性,就称为关联。数据关联是数据库中存在的一类重要的、可被发现的知识。关联分为简单关联、时序关联和因果关联。关联分析的目的是找出数据库中隐藏的关联网。一般用支持度和可信度两个阀值来度量关联规则的相关性,还不断引入兴趣度、相关性等参数,使得所挖掘的规则更符合需求,能够支持发现同一事件中不同项目之间的关联规则。
2.序列关联分析
序列模式与关联模式相仿,差别是序列关联分析把数据之间的关联性与时闯联系起来。
3.聚类分析
聚类是把数据按照相似性归纳成若干类别,同一类中的数据彼此相似,不同类中的数据相异。聚类分析可以建立宏观的概念,发现数据的分布模式,以及可能的数据属性之间的相互关系,能够有效地把数据划分到不同的组中,组之间的差别尽可能大,组内的差别尽可能小。与分类模式不同,进行聚类前并不知道将要划分成几个组和什么样的组,也不知道根据哪几个数据项来定义组。
(二)数据挖掘建模流程(CRISP-DM)
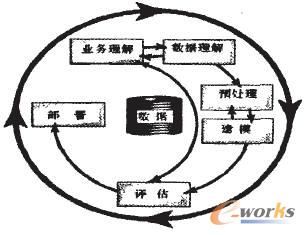
图3-1 CRISP-DM过程模型
专题分析产品大都是基于数据挖掘技术来实现的,所以每个专题分析产品也可以看作一个数据挖掘项目。我们所进行的所有的专题分析严格遵照业界流行的CRISP-DM(CRoss-Industry Standard Process for Data Mining)过程模型。CmSP-DM模型中各个阶段的要点为业务理解、数据理解、预处理、建模、评估和部署。
CRISP-DM过程模型从数据挖掘技术应用的角度划分数据挖掘任务,将数据挖掘技术与应用紧密结合,更加注重数据挖掘的模型的质量和如何与业务问题相结合、如何应用挖掘出的模型等实际应用中用户最关心的问题,因此CRISP-DM过程模型从商业的角度给出了对数据挖掘方法的理解。
(三)数据挖掘应用情况
针对金融企业的业务。数据挖掘技术主要应用于以下几个领域:
1.业务预测
(1)背景
由于金融企业推出的产品日益明细、种类繁多.因此应用预测方法的场合也很多。例如为了确定未来的市场规模,需要对各类金融产品的利润做出预测;为了确定下一年的发展目标,需要对各种业务的增长做出预测等。
(2)需要的数据
根据预测主题的不同,预测所需要的数据也不尽相同,预测所需要的数据主要是与预测主题相关的历史数据。
在具体应用时,所需数据还与所选择的算法以及算法所需的参数有关。例如,针对下一个月业务量的预测,可以使用时间序列分析,也可以使用神经网络中的BP算法(反向传播方法)进行预测,还可以使用简单的统计方法(例如移动平均法);而每种算法还可以采用不同的数据粒度,采集不同的数据样本。例如以过去12个月的数据为样本,以月为单位;或者以过去3年的数据做样本,以季度为单位。
(3)应用的主要挖掘算法
时间序列分析、神经网络预测和简单的统计方法(移动平均法、修正的移动平均法等)。
2.大客户、优质客户特征的识别
(1)背景
企业的大客户群体往往是利润的主要来源,大客户、优质客户资源是金融企业竞争力的重要体现,也是其他金融企业争夺的焦点。识别出大客户、优质客户,为他们制定针对性的措施,提高大客户、优质客户的忠诚度,是金融企业继续保持领先的关键所在。
金融企业经营分析支持系统中的数据挖掘工具应该具有识别大客户、优质客户及其行为特征的能力。不仅能够根据现有数据来判断用户是否为大客户,还应该根据现有大客户、优质客户的资料,提取出大客户、优质客户的特征,以及客户问的关系,发现潜在的大客户及优质客户。
(2)需要的数据:帐户数据、交易数据及相关历史数据等。
(3)应用的主要挖掘算法:聚类分析、分类和神经网络算法。
3.客户群体的细分
(1)背景
客户群体的细分有两类方法:分类和聚类。其中分类分析方法是指事先人为根据客户属性确定分类标准,再对用户进行归类。聚类分析方法是指系统根据客户属性,使群内客户具有最大的相同性、群间客户具有最大的相异性,自动产生聚类标准,再按此标准对用户进行归类。数据挖掘系统应可以在客户群体细分的基础上进行进一步的细分,直到所需要的粒度,并由此对客户群进行各种分析。
(2)需要的数据
客户群体细分需要以下数据:客户交易数据、账户数据、业务属性数据、客户自然属性数据和相关历史数据及其它数据。
(3)应用的主要挖掘算法:分类、聚类分析和神经网络算法。
五、结束语
通过建立一个基于数据挖掘企业级的经营分析决策支持应用的平台,提高企业的业务支撑能力,丰富企业的业务应用内容,全面实施客户关系管理,为客户提供个性化服务。同时为管理和决策提供强有力的依据,全面提高竞争能力,增强企业整体盈利能力。
随着计算机计算能力的发展和业务复杂性的提高,数据的类型会越来越多、越来越复杂,数据挖掘将发挥出越来越大的作用,只有从数据中有效地提取信息,从信息中及时地发现知识,才能为人类的思维决策和战略发展服务。